

Advanced Capture as Data Science: what does it mean to achieve 99% accuracy for data extraction from your documents?
Increasingly, the mainstream media and the technology media are covering the topic of data science. This is primarily driven not by the “big data” projects, but by efforts to apply machine learning to problems of all types.
The “science” is mostly concerned with how to accumulate and verify the quality of input data. And then, the focus is on how to evaluate the resulting output of machine learning to determine that the output is valid and representative of the problem being solved.
Evaluating Output from Machine Learning
As always, this is a lot easier said than done because it is difficult and expensive to identify if there is any bias in the input or output. When it comes to advanced capture, we have to similarly scrutinize the input and output streams in order to verify that the system is working effectively and as expected.
Sample Data Input
For instance, most organizations adopting advanced capture hope to configure a system using a few samples of production documents. When quizzed on whether the samples being used for configuration are statistically representative, the answers often fall short. This is due to the fact that often there is little understanding of the factors involved in identifying the requirements for a representative sample.
Sample production documents must account for variances in image quality (e.g., if the document is scanned), document variety (e.g., a contract vs. an invoice), and the variance of data and format of each document type. As the variance in documents increases, so does the required sample size. If your input data is skewed too far one way or another, the result is less automation and more manual exception handling.
Examining Overall Accuracy
One particular aspect of advanced capture performance, and arguably the most important one, is overall accuracy. We often hear requirements of 95%, 98%, and 99% accuracy. However, when we delve into what that actually means or how the client would calculate it, there is no clear answer.
Believe it or not, with all advanced capture systems, there is not one single accuracy number, but several. Let’s review them.
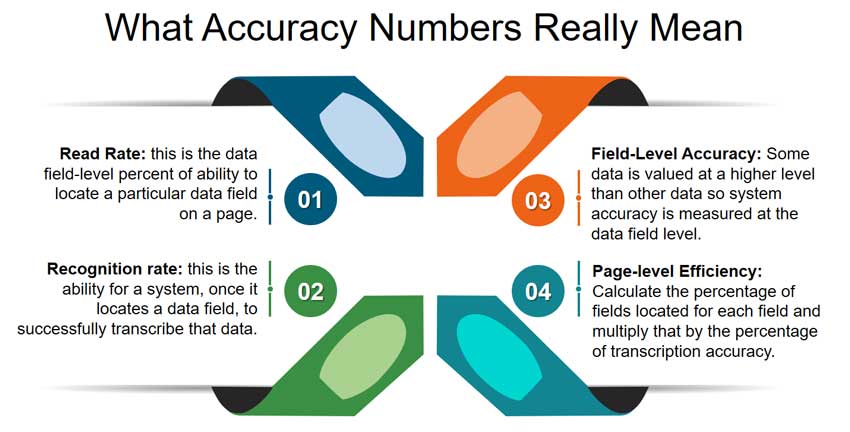
What Accuracy Numbers Really Mean
Read Rate: this is the data field-level percent of ability to locate a particular data field on a page. For structured forms where there is good image quality, the percentage can be quite high, as high as a 95%-99% location success rate. For variably-structured documents such as invoices, success rates are typically lower, depending upon the system’s ability to apply the appropriate algorithm to locate any single data field.
Recognition rate: this is the ability for a system, once it locates any particular data field, to successfully transcribe that information. For text, transcription success can measure in the lower to mid-90%. For handwriting, the upper 80% is often the ceiling, depending upon the data type.
When multiplied together, you can obtain the overall accuracy of the system. For instance, if overall read rate for all fields of a test deck of documents is 89% and the recognition rate for those located fields is 90%, then the total performance of the system will be 80.1%.
Field-Level Accuracy: However, it doesn’t have to stop there, and it typically doesn’t. Some data is often valued at a higher level than other data. Therefore, the accuracy rates must be higher. So the system accuracy would be measured at the data field level instead of across all of the fields.
Page-level Efficiency: If the organization wishes to understand page-level efficiency, they would calculate the percentage of fields located for each field and multiply that by the percentage of transcription accuracy.
So you might be wondering how any advanced capture system can provide 99% accuracy? If you are measuring at the overall level, the truth is that it cannot. The current state of technology isn’t near the level of a human and humans cannot deliver 99% accuracy.
Achieving 99% Recognition Accuracy
What can be done is to “decouple” the read and recognition rates to achieve 99% recognition accuracy for some proportion of successfully-located data. We can achieve this through the use of field-level confidence scores, which allow us to statistically control the quality of the data at a field level. The result is data that can flow through at rates as high as 99%. The trade-off is that the amount of data will be a lower percentage than the overall amount of data located and recognized.
As you can see with advanced capture, there is a lot to be considered when using a data science approach. With the increasing adoption of machine learning, implementing a process that includes data science will go from a recommendation to a necessity.
###
If you found this article interesting, you might find this industry brief and these best practices of interest:




