
Over the years, recognition technology companies (including Parascript) have attempted to create acronyms to delineate the differences between OCR, ICR, and the technology needed to effectively read many types and styles of handwriting, including cursive. In the end, we havent run into anybody who asks about natural handwriting recognition and the such. People just ask about ICR. The following is a short overview on the differences between OCR, ICR and unconstrained and cursive handwriting, which is what you get with ICR from Parascript.
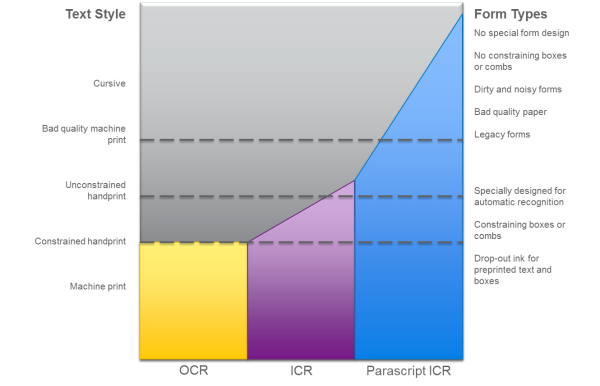
Evolution of Recognition Technology
OCR
Optical Character Recognition (OCR) examines scanned images of machine-printed text and translates the characters into ASCII text files. Though most advanced systems are able to recognize almost any type of font, they deal only with machine printed characters and reject all handwriting. Machine-printed letters are evenly spaced across, and up-and-down on a given page, allowing OCR systems to read the text one character at a time. Once all characters in a word are recognized, the word is compared against a vocabulary of potential answers for the final result. Any text that is less than perfect will cause even the most sophisticated OCR systems to return significant reductions in accuracy when processing degraded images. For example, when characters break apart due to poor image quality, or if multiple characters merge due to blurred or dark backgrounds between them, recognition accuracy may be reduced by as much as 20 percent.
ICR
Intelligent Character Recognition (ICR) tends to be generically used with reference to all types of handwriting recognition, however from a technical perspective; ICR is the ability to recognize constrained hand-printed characters.
Not surprisingly, interpreting the patterns of human writing is far more complicated than converting simple machine print, because no two people ever write identical characters. Factors such as mood, environment, or stress all conspire to create variations in character writing, causing individuals to form characters differently each time they write. As with OCR, ICR engines execute recognition character-by-character and start by segmenting words into their component characters. Because ICR technology recognizes separate words or word combinations, such as form fields, letters cannot be written sloppily or stuck together.
While ICR is more robust than OCR in handling human writing, dictionaries are employed after the recognition process, not during it. Therefore, if a correct guess was not generated during the character segmentation and recognition process, validation with vocabulary lists does not improve the result and significantly reduces accuracy.
Parascript ICR: unconstrained handprint and cursive recognition
Both OCR and ICR deliver high accuracy when analyzing constrained text but are ineffective when dealing with unconstrained or cursive writing, where letters are linked together, and may be poorly written or even illegible. Parascript ICR technology recognizes that the features of handwriting have a dynamic pattern. Handwriting, when reduced to its most basic element, is essentially motions made by a writing instrument. Certain symbols embody the essence of all handwriting styles, such as the strokes that describe the trajectories. Parascript calls these strokes XR elements and they are found in all letters. Combined, XR elements form virtually all letter shapes.
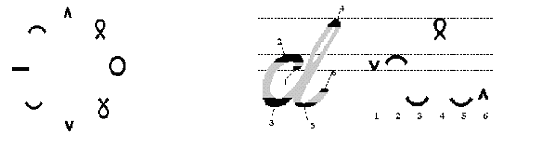
Parascript’s XR Elements
Parascript ICR technology focuses on the anatomy of a written word. Much like how humans use context to read words that have been partially scrambled (yuo cna lkiley raed tihs wthiuot a pborlem), The Parascript ICR engine achieves similar recognition through a context-driven approach. By referencing results databases during the recognition process, Parascript ICR builds highly accurate answers which, in turn, lead to substantially higher recognition rates than engines which only validate answers at the end of the process.
This process is also helpful in achieving recognition of machine print that is too poor for an OCR engine to recognize.
Summary
We hope this simplifies the differences between the types of OCR and ICR. What questions do you have? How have you heard the terms OCR and ICR referenced?



