
I’ve written about this before but the topic always deserves a revisit, especially since so many solution providers in the intelligent document processing (IDP) market claim to provide very simple deployments. And why not? Is there anyone looking for something overly-complex? I think not.
But it is a far cry to claim a super-simple deployment and quite another to actually deliver it. In many cases, the gambit is that by the time prospective customers sign on the dotted line, they’ll be too committed to reverse course from a solution that is not meeting expectations. You might be shaking your head in disbelief but unmet expectations is almost a feature of enterprise B2B sales. And in IDP, it is no different. If you canvass organizations that have adopted some form of IDP, whether from a “legacy” vendor or from what I call a “machine learning-first” provider, you often find a common trait – there’s a lot of automation of data entry but not a lot of data that goes “straight-through” untouched or unreviewed by humans. I often like to use this picture to explain the difference between a fully-manual process, an automated data entry process, and something that pushes the limits of automation:
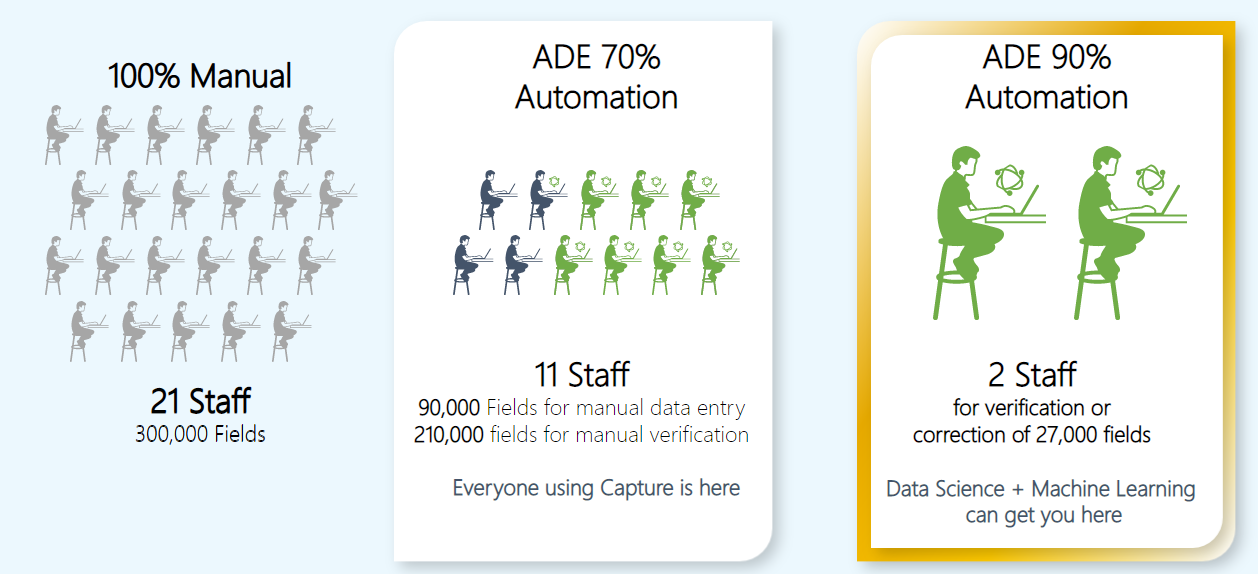
The difference between shaving off 50% of your costs and getting greater than 91% automation is all in the effort taken to configure, test, and optimize the software. But doing that takes a lot of effort, even in the days of advanced deep learning.
You need to spend time collecting and tagging a lot of data. And then you still probably have to spend quite a bit of time doing that configuration, testing, and optimization. Organizations just don’t have the skills, time, and money to do it so IDP adoption is limited to large-scale needs. Enter solutions that claim to reduce the need for large training sets and that eliminate the need to configure. So how does it work?
Reduced Training Data
There are two ways to reduce the need for training data: you either contract with a vendor that has pre-trained a system on some level of fundamental data or you work with a solution that has been pre-trained and optimized. They sound similar but they’re not.
In the latter case, a pre-trained and optimized system, a vendor will often take tens or even hundreds of thousands of carefully curated sample sets and train a system to perform tasks at a high rate of precision. Parascript provides these types of pre-built capabilities for checks, invoices, and other types of tasks. We have taken on a significant investment in data curation, training, and optimization so you don’t have to. But what an organization gains in terms of ready-to-deploy, highly-optimized technology, it loses in that there is no ability to tailor the automated tasks to a specific set of requirements; you take what you get.
In the case of the former, systems are trained to understand things like dates, amounts, and other well-formatted data – but not on specific use cases for specific documents. They might even be trained to identify entities like cities and states. The thinking goes that if these systems bring something to the table in the form of this “pre-training”, it reduces the number of samples required to learn this type of information leaving any efforts required focused on training for specific use cases. For example, if a system already understands dates and how to find them, training is focused on how to discern one date from another.
And to some extent, this hypothesis has been borne-out. Parascript Smart Learning is pre-trained on a number of concepts involved with document-based information. With this level of “primitive” data already understood by the system, an organization doesn’t need to spend as much time defining this data and training it with larger sample sets. But these systems, as implied by my example above, still require optimization in order to deliver precision. For instance, a system might be trained to recognize a date field, but that system will not be able to discern a service rendered date from invoice date on an EOB. And presuming there is a lot of variance with where those dates are located and how they are labeled, you need more examples so that the system understands where to look. The upside is more of this optimization using larger sample sets can be undertaken during production instead of taking additional time and expense before the system is deployed.
Ultimately we’re still not at a state where systems can configure and deploy themselves at high levels of precision without requiring some work by you or your services company, but we are getting closer to enabling organizations to achieve high levels of precision automation with the least amount of effort.


