

We caught up with Tatyana Vazulina, the Product Manager at Parascript, to understand why truth data is so critical to ensuring quality results in OCR capture and recognition. What follows is our edited interview that captures Tatyana’s latest tips on advanced capture, OCR and ICR for the highest quality data results.
First of all, let’s start with the most basic question: why automate?
When companies look to maintain and grow their business, they basically have three choices for document processing: manual data entry, automation or a combination of the two, which is what we recommend. Relying solely on manual data entry is expensive, slow, error prone and ultimately difficult to scale in a cost effective way. Completing rote tasks, operators can get sick, tired or distracted, which is when they make more and often inconsistent mistakes. Manual data entry operators make fewer mistakes earlier than later in the day. By contrast, when there are errors in the recognition engine, they are consistent. The recognition engine handles the rote tasks of data location and extraction with higher accuracy faster, while human operators excel at the complexities, such as handling the exceptions routed to them.
How do you determine the accuracy of your automated processes?
When we talk about accuracy in this context, we mean the number of errors in the accepted results. Accuracy of 99 percent is the same as a 1 percent error rate. With the recognition engine, you’ll want to set your target level of accuracy for the different document types that you’ll be processing. Lower accuracy requirements means a higher percentage of the results will be accepted by the recognition engine as correct. Higher accuracy requirements means a lower percentage of results will be accepted by the recognition engine as correct.
In data location and extraction, it’s impossible to talk about accuracy without discussing confidence values, thresholds and truth data.
RECOGNITION ENGINE: ACCEPTED AND REJECTED RESULTS
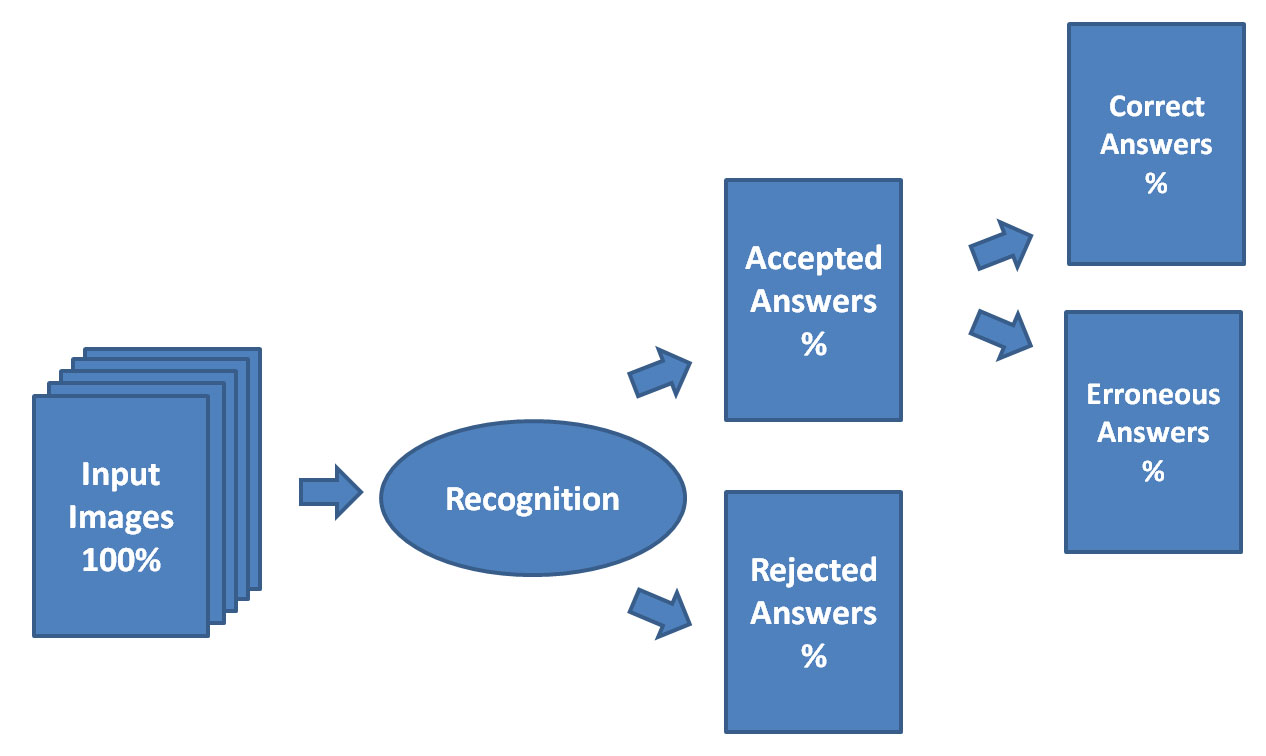
How do we achieve accuracy in automation?
To maximize accuracy, you need “truth data.” This is the set of data on sample documents that represents what the actual recognition answer should be. Truth data needs to be as close to 100 percent correct as it can be because it is used to fine-tune the recognition engine and validate results.
Once you have this data, you can test the recognition engine to see how it works across your documents. Once you can see where the lines are drawn among data that is located and recognized correctly, data that is located but recognized incorrectly, and data that is not located at all, you can then set thresholds using confidence values that determine when data can go “straight through” with no additional validation and what data needs extra massaging either through additional data checks or through human review.
How do you establish your truth data?
With existing data entry operations, the output from the data entry process can be used as the ground truth data once it undergoes extensive quality control. This must be a large set and representative of the diversity of document types. Another common way to get this truth data is to review each sample document and manually record the actual data. Manual data entry operators and SMEs dedicate time to review each sample and enter the correct data. When the accuracy rate needs to be high, this may require re-keying as well. Having this truth data is crucial to tuning the software to meet specific accuracy requirements. Without it, there is no way to provide any real assurance about recognition accuracy.
Once we have our truth data, how do we determine our thresholds—the confidence value—for accurate results?
Thresholds are determined by selecting a certain confidence value as an acceptable threshold for what are determined to be reliable results. A confidence value is an aggregated parameter that is calculated using a complex algorithm, which considers many variables. Confidence values vary depending on factors such as the specific data quality, type and complexity, or how the data is being used. The confidence value scale shifts based on the specifics of the data being extracted and the document type. Every recognition result has a confidence value associated with it. This confidence value is a number ranging from 0 to 100 on a sliding scale. It helps to visualize the data as a table where the threshold is set on the confidence score based statistically at the point when an unacceptable amount of answers are accepted that are incorrect than correct.
DATA VISUALIZATION: SETTING THE THRESHOLD
| Images | Recognition Answer | Confidence Score | Truth Data |
| Image 1 | Gray | 98 | Gray |
| Image 2 | Blue | 98 | Blue |
| Image 3 | Red | 97 | Red |
| Image 141 | Green | 76 | Gray |
| Image 3678 | White | 68 | White |
| Image 489,000 | Yellow | 67 | Magenta |
The challenge is establishing where to set the threshold in order to achieve the required accuracy. The higher the chosen threshold means there will be a lower number of accepted results with higher accuracy. To establish the right confidence value as the threshold for each document type requires ground truth data.
Key Truth Data Tips to Improve Recognition
Do you have any tips or best practices that you can share with us about truth data and improving recognition?
Basically, I have three tips for starting out:
- Make certain the number of documents in the set is sufficient and fully representative of all the documents that you want processed. Determine the number of documents based on the level of accuracy required for the project. For example, when processing 100s of thousands of documents, the truth data set must be large enough to represent variances in document types, image quality and other variables.
- Ensure the quality of the documents is taken into account. The set of documents should be representative, not just in terms of their number, but in the quality of the documents of this particular field, the variety of character styles, and the variety of words that may be encountered in the field.
- Process your documents and determine a confidence value for the threshold. Examine the confidence values with the number of images and the number of incorrect results based on truth data. You can easily change your thresholds to fine-tune the system for your target accuracy rates.
Different tasks require different levels of accuracy to achieve acceptable results. Setting the threshold to reflect the task and project accuracy requirements requires fine-tuning.
In Summary: Truth Data and Measurability
Truth data allows for objectively measuring the accuracy of your automated data location and extraction, and understanding how well it performs. With ground truth data and advanced data extraction using machine learning, the net result is higher quality data and performance that improves as more data is fed into the system.



