
The goal of every recognition engine is to produce the highest accuracy possible which is probably pretty obvious (who uses technology to get poor results?).
But did you know that the type and quality of images being recognized can and often produces significantly different results, depending upon which recognition technology is used? For example, in the case of constrained handprint, the more distinct the individual written characters are in the image, the more closely matched are the results of each method.
On the other hand, and this is far more typical, if the individual characters are more ambiguous and illegible or resemble others characters as in the case of unconstrained handwriting that can mix-up hand print and cursive styles, the greater will be the difference in the recognition rates and accuracy of the recognizers. To produce better results on poor quality images and hard-to-read characters, advanced handwriting recognition technology employs the use of dynamic vocabularies.
For example in the image below, which was extracted from a form field, is the age of a dependent child under age 21. On the form, if the child is over 21 then the field is left blank. Because of this context information, it is clear that the date in the image is 08-02-98 even though the digit 9 looks more like a 4.
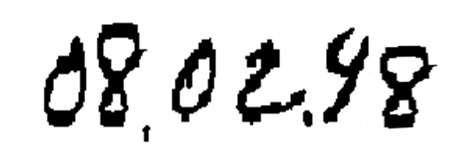
Having defined the correct answer, lets consider what would be the differing result of recognition without vocabularies, static vocabularies, and dynamic vocabularies.
A recognition engine working without a vocabulary will read 08-02-48, which is clearly incorrect.
A recognition engine working with a static vocabulary (look-up table) to perform post-recognition validation will often fail to produce a correct answer as well. This is because it may produce only one answer (4) for the first digit of the year.
Fortunately, recognition with dynamic vocabularies allows the recognizer to determine, DURING THE RECOGNITION PROCESS, that there can’t be digits other than 9, 0, or 1 in the year position. Even though the symbol looks like a 4, 4 as an option is not possible and will be excluded from the recognition process. The result is that a 9 will be the answer.
Lets look at another more difficult example, this time with letters instead of numbers. In the image below, it is not clear if the first symbol is a d or a combination of a c and an l. Recognition without vocabularies would not produce a reliable result.

Use of a static vocabulary approach would require that both hypotheses are produced and stored until the end of the recognition process when validation based upon the look-up table takes place. If the word were longer, there would be more hypotheses. These hypotheses would need to be stored and analyzed. The result would be slow and would potentially yield lower recognition accuracy. Why bother if you only can get the wrong result, right?
Using dynamic vocabularies, there is no necessity to analyze and store all possible hypotheses of segmentation. If the dynamic vocabulary does not contain a combination of c and l at the beginning of the word, the only possible segmentation solution is d.
There are a lot of examples and stories of poor handwriting recognition and the lack of dynamic vocabularies is a big reason. But using the proper technology for the job, there are just as many good stories of successful use of handwriting recognition.
Hopefully its a bit more clear that dynamic vocabularies have the ability to produce higher recognition accuracy over what a lot of people have come to expect.
Learn the latest in automated handwriting recognition technology in the free white paper Automating Handwriting Recognition Not all ICR software is created equal.



