
Fax machines – a relic of the mid-twentieth century yet they are still going strong due to the ease of use and relative security. Yet when it comes to fax machines within a document-oriented workflow, they present a significant impediment to automation. Nowhere is this more apparent than in healthcare where all manner of documents are shared across different stakeholders including providers, payers, and services providers to support prior authorization, claims submission, medical reviews, and reimbursement.
Achieving high levels of automation is hard enough, but when faxes are involved, multiple issues crop up. When documents are faxed, they are most often converted into bitonal images the process of which introduces a lot of quality issues. These include:
- Scaling Issues – the form looks as if it was shrunk down, occupying a smaller portion of the page frame.
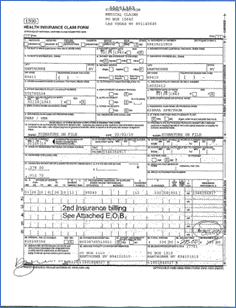
- Shifting Issues – the introduction of a tracking number at the top, while not readily noticeable, causes the entire form to be shifted downward.

- Noise Issues – we see the conversion process created a lot of background noise that can interfere with an OCR process to extract this field data.
![]()
Once upon a time, we all thought the problem with capturing data from images was solved through what is often called “drop-out forms”. These forms were pre-printed with a special red or blue ink. The actual data would be typed or printed on top of the form in black ink and when captured with a compatible scanner, the pre-printed text would disappear leaving only the data. Here’s a before and after example of a red drop-out form and the result of removing the form structure leaving only the data.


The benefit was that any pre-printed form structure could get in the way of using OCR to automatically extract the needed data. And it worked well. That is when providers spent the additional money on more expensive drop-out forms and payers received these forms via mail and used compatible scanners. But in practice, fax machines turned those drop-out forms into, you guessed it, bitonal, ugly images.
So not only does the form structure stay intact, impeding OCR accuracy, but the fax machine introduced all of those quality problems.
Enter Virtual Drop-out
Just as the imaging industry solved problems associated with poor image quality form scanners, the IDP industry, led by Parascript, has solved the fax problem using a new deep-learning technology called virtual drop-out. Here’s how it works.
- Using hundreds of thousands of real-world fax examples, we train deep learning neural networks on what a claim form looks like and how to discern between the underlying form structure and the actual data.
- And while we’re training, we also provide guidance on what represents a high-quality image from the noise, scaled-down, and shifted nightmares out there.
- The deep learning algorithms then go to work analyzing the differences between the good and the bad forms, identifying different ways to correct for different problems. All in all, there are over 100 different image quality issues that can be encountered.
- Then the algorithms start making the corrections, first aligning poor faxes, recalibrating the size and orientation of the forms, and then actually erasing the form structure.
The result is pretty astounding. Here is an example of a noise, scaled, and shifted form before and after applying Virtual Drop-out.


A picture is worth a thousand words and in this case, many thousands of dollars in cost savings through the ability to handle even the hardest cases of faxed, bitonal claims with as much precision as a high-quality scan.
Come see what we can do for your organization on any type of faxed document.


