

This third article in our Straight Through Processing (STP) series focuses on the concepts important to understanding what type of STP is possible in document automation and explores how to achieve optimal levels of processing.
In our previous STP series article, “Exploring STP: Why It’s Important,” we discussed how approaching complex automation tasks such as document automation require a data science approach to create a system that has predictable and reliable output. It is not simply a case of 100% pass or fail. Rather, there are subtleties that have to be uncovered.
Rethinking Traditional RPA
Approaching document automation requires a different level of thinking than “traditional” RPA automation. First, the notion that you can achieve a pass-fail at the page or document level for activities that involve automation of data entry is not possible. Even with today’s advances in machine learning, the probability that any single page will enjoy 100% accurate data location and extraction is very low: less than 5%. Only with page or document-level classification (where no document separation is involved) can you apply such a “binary” approach. For data extraction where there are multiple chances of success or failure on a single page, automation must be measured at a data field level, not a page or document level.
As an example, let’s take a flexible spending account process where the goal is to automate location and extraction of five key data fields on receipts of various sizes and formats. If we expect a high percentage of receipts where all data is accurately processed, then this would be the wrong approach. Even the most refined deep learning algorithms would have problems reliably locating and outputting all five fields on a majority of receipts. Maybe 5% to 10% of receipts would have complete success. However, it could locate and output 85% or greater of all fields of all receipts. It looks something like this (these numbers are hypothetical, but based upon real tests):

So looking at any data entry automation project in terms of a full page or document is not ideal because most pages or documents will require some level of review.
Designing and Measuring a System
Second, you cannot design and measure a system based solely on the ability to achieve either a pass or fail 100% of the time. This is unlike designing automation for very rote, defined tasks for which it is easy to determine pass/fail scenarios. When it comes to employing “cognitive” types of computing, we have to deal with predictions, not absolutes. Machine learning makes mistakes that are hard to plan for or comprehend. The more complex the task is, the more complex the potential outcomes. For any particular data field on a page, there is a probability of a system’s ability to achieve success.
Confidence Score and Thresholds
This is where the concepts of “confidence scores” and “confidence thresholds” come into play. For any advanced capture system, the output for each answer will be accompanied by a confidence score. This score is based upon a lot of inferences such as complexity of the location, whether or not there are other candidate answers, range of potential answers, and many more. Confidence scores are meant to be used to construct a statistical measure of all output so that it is possible to create a boundary score, often called a confidence threshold, which determines with a certain level of precision whether output for a given field is correct or not. Without use of confidences scores, we would have to manually review all output – that certainly doesn’t sound like straight through processing.
STP Measured at the Data Field Level
The amount of straight through processing needs to be measured at the data field level and requires identification of confidence thresholds for each data field type in order to automatically identify good data from bad.
This means that workflows employing document automation should emphasize review only on the data fields that require it. The remainder should be shuttled straight into downstream processes. Overall benefits are measured not on how many pages or documents can move straight through, but how much overall data entry is removed from the equation. It stands to reason that if an organization is performing data entry on 100 million data fields per month, reducing 50% of that workload at a data field level presents significant value.
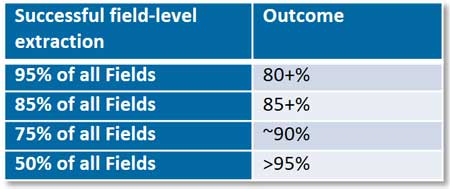
Let’s take another look at the amount of automation that can be achieved for the above review process. This time, let’s focus on the total percentage of fields instead of total number of receipts (again, this is hypothetical, but based upon real tests):
Looking at Efficiencies
Looking at efficiencies at the data field level, we can see that there is an 85% probability that 95% of all data fields can be correctly located and extracted. If the number of fields is 100 million, that means almost 81 million data fields do not require data entry or review. That is a significant level of automation.
###
The first and second articles in our STP series are “Attended and Unattended Automation for Document Processing” and “Exploring STP: Why It’s Important.”

For the latest trends in intelligent document automation, check out this infographic, “Intelligent Automation Trends: How the Digital Workforce Takes Advantage of Document Automation Solutions,” based on the recent AIIM Survey of 100 leaders in capture.


