

If you have worked with OCR software, then you have probably heard—and even made use of—a “confidence score.” OCR software provides character-level and word-level confidence scores. These scores provide the developer an indication on whether the OCR software believes the answer to be correct. However, the scores are not representative of probabilities so an 80 score does not mean “80 percent correct.”
True Automation and Confidence Scores
These scores can be useful but when it comes to actual data extraction and not simply converting an image to text, another confidence score comes into play: the data field confidence score. This score uses the raw OCR character and word-level scores and synthesizes them with other available information to arrive at a final score. This other information can be data type (e.g., numeric, letters), format (e.g., phone number vs. credit card number), etc. When it comes to achieving true automation, these confidence scores are critical; unfortunately most solutions are not able to support true automation. To understand why and the potential significant negative impact on your project, read on.
Consistent Scoring Mechanisms
When it comes to this final score, everything depends upon the software having a consistent scoring mechanism for a given document and data type. For instance, the field confidence score for the “Date-of-Birth” data element on a claims form should output a consistent range of scores based upon the reality of the answer being correct. A correct answer should always have a higher score than an incorrect answer and vice versa. This consistency over a large number of inputs allows the developer to understand the break-point at which data is correct vs. incorrect. The break-point cannot be determined with only a few samples. The number of samples needs to be statistically significant.
The picture below illustrates such a scenario where all answers with a score equal to or above 74 are correct. In reality, no system can achieve 100 percent accuracy even for identifying incorrect scores, so you will see that one answer above that break-point is incorrect and one answer below that same point is correct (among incorrect answers). This ability to determine break-points which we call confidence thresholds, allows true automation of data extraction, which completely removes the need for verification for the majority of data. Only data identified as highly probable of being inaccurate is reviewed.
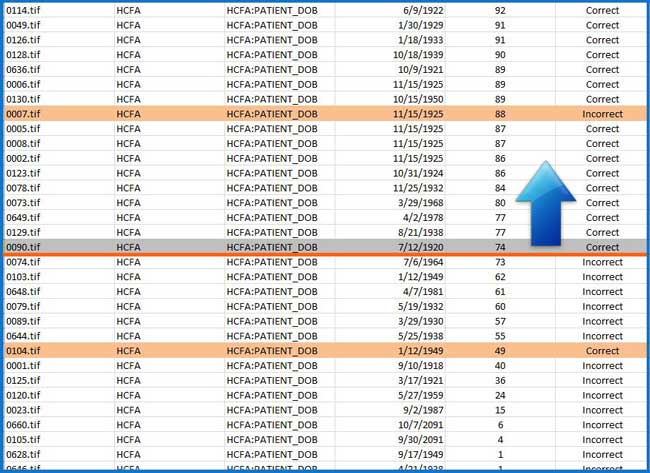
Advanced Capture: Field-level Confidence Scores & Confidence Thresholds
Many OCR software solutions do not have this consistency of field-level confidence. The most common reason for this is that the level of tuning required beyond character and word-level scoring is very costly and requires a lot of expertise. We can see an example of score inconsistency in the image below:
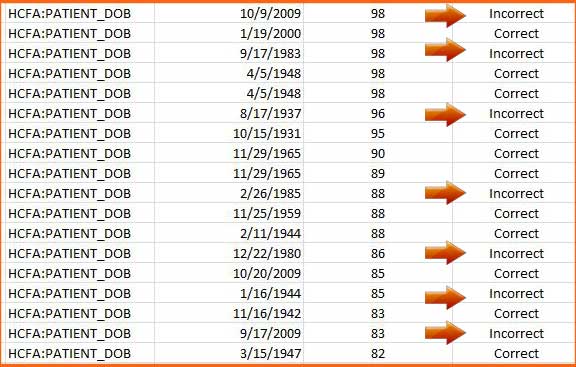
Many OCR Systems | Inability to Set Confidence Threshold
We see many answers with the same score displaying different results. When sorted, we cannot establish a threshold at which to create this accurate vs. inaccurate break-point. The result is that many systems cannot provide the level of certainty needed to identify those critical break-points allowing data extraction to be truly automated. This shortcoming has two likely effects:
- All data is forced to go through manual review. Even if most of the data is correct, the extra time required to review it is very expensive, and the labor required can actually prevent those reviewing the data from actually catching incorrect values, thereby raising error rates.
- Data errors are missed. Companies using inconsistent confidence scores for establishing thresholds are unknowingly incurring a lot of data error.
Both of these can have significant adverse business impact. At Parascript, we focus on optimizing the field-level score consistency so that your organization can turn its focus and efforts on where it is really needed. In many cases, we can deliver optimized systems from day one.


