

Tapping into the power of information requires that your document processing outputs high quality, reliable data. Unfortunately, most capture and recognition engines focus on read rates, not error rates. This means that the only way to ensure accuracy is to manually verify that it’s all correct. Such rigor is usually cost prohibitive and too time-consuming so businesses spot check or do manual verification when an issue is identified.
Many recognition engines rely on templates to achieve higher rates of accuracy, but templates are brittle and only work well when there aren’t any new document types or images feeding into the queue. In dynamic production environments, new document types and changed formats are common occurrences and can throw a wrench in any template-based system.
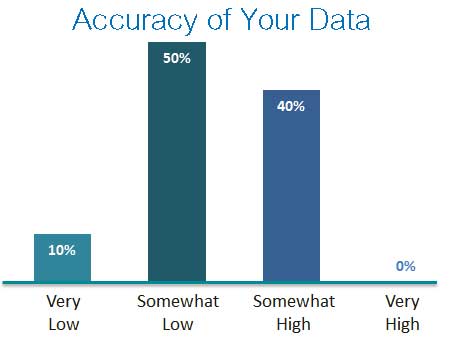
When leaders at the top BPOs were asked how they rated the accuracy of their data results from document processing, 10 percent rated results very low with 50 percent rating their results as somewhat low. (To learn about all the results from this 2017 survey, please attend the upcoming SIG Webinar on May 4.)
Data Quality: What We Talk About
Management concerns come from real world experience facing the challenges of low quality data that have immediate effects and downstream effects that can be costly to the business in Operations and ultimately customer satisfaction and loyalty. So what’s important to evaluate when looking at improving initial data extraction?
What we talk about when we talk about data quality requires focusing on four areas:
- Read Rate is the percent of extracted data from all the available data.
- Accuracy is the percentage of extracted data (the read rate) that is accurate. Error rate is the percentage of extracted data that is erroneous.
- Acceptance Rate is the percentage of extracted data that is allowed to flow through the system at a particular error rate. Any data that meets or exceeds a specific threshold will be accepted.
- Ground Truth Data is a sample set of documents or images and verified extracted data (truth data) results that allows you to objectively measure your capture engine to understand how well it performs. Continuously adding to your samples and truth data allow you to measure your system over time.
Automated Interpretation
Automated recognition and interpretation of data can provide highly accurate results with very little manual verification. This is achievable through using a state-of-the-art recognition system that leverages machine learning and providing the engine ground truth data so that it can develop the necessary context and generate appropriate business rules that reflect an ever-changing production environment.
Keeping the ground truth data refreshed allows the system to develop new rules that ensure continued data accuracy.
If you found this interesting, check out our latest eBook on data quality:



