

Different document types and their attributes affect the strategies for locating and extracting data. Structured forms are highly-standardized documents designed to collect specific data. The forms are typically issued from a single organization, and there is tight control over form versions and the data required. These types of forms initiate a wide variety of business processes, such as obtaining a driver’s license, getting a building permit, financing a loan or submitting a medical claim.
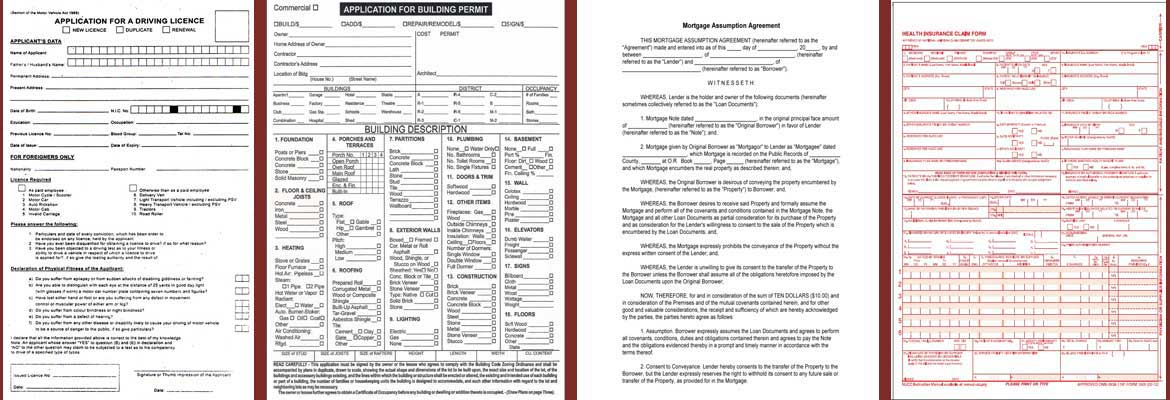
The key here is that, with the exception of different versions of a specific form, the location of the data and the expected types of data are always known. This makes it much simpler than more complex documents that have higher variability. With any data extraction problem, the first challenge is to locate the data, and in this case, we know quite a lot with good precision.
Locating the Data: Selecting the Right Approach
The technique to locate data on a structured form is almost universally the same, but it may be named differently depending upon the vendor or services provider offering the solution. Names include “zoned fields” and “coordinate fields.” The underlying technology is always the same: the software is supplied with X and Y coordinates of the expected location of the data and then extracts the data that is found in that location.
Full-page OCR Approach
Notice that the technique to locate data is typically the same and not to“extract the data.” When it comes to performing recognition on a field, there can be different approaches—each with their own pros and cons. The first approach is to run a full-page OCR on the document including formatting and then locate the data at the provided coordinates. The ability to do this really depends upon the level of the OCR engine capability and the fidelity of the output formatting. If formatting is off, then the results, even if the OCR engine is accurate, will be poor. Also running full-page OCR, even with today’s higher-performance computers, still has a performance/time penalty. If you don’t need to have all the data or the additional formatting, why pay that cost? The good side of fully-formatted OCR output is that you now have a document that can be sent to a document management system and be full-text searchable.
Image Coordinates Approach
The other mechanism for location is to use the coordinates on the image itself instead of the formatted OCR. In this way, only the data that needs to be extracted is put through the OCR engine, which can speed things up considerably. Both techniques are sensitive to the scale of the image. If the image is distorted, then the pre-defined coordinates will not properly overlap with the data on the page and result in poor results. So attention to how the image scales is important, especially if you have a multi-channel input system that includes different modes of capture from mobile, scanner, and fax. Each can have different resolutions that result in different sizes of images.
Image Scale and Adjustment Techniques: Pros & Cons
Many software applications have the ability to examine the scale of the incoming image and adjust the size to conform to the expected size. This can work, but can also degrade the recognition portion is the image becomes too stretched or distorted. Another technique is to take a sample template form image that is the expected scale and attempt to align incoming images with this template. This can help to detect distortion since a stretched image will not align correctly with the template image. The benefit of detection is that it can be handled as an exception without attempting to perform recognition. Some software can even break-up documents into multiple sections and align with the corresponding sections of the template. This can significantly improve the issues resulting from automated scaling since potentially only the distorted portion of the image is altered.
Dealing with the Noise
What apart from scale is important to track when tackling a structured form project? Form field “noise” is one area that is common. This noise typically takes the shape as parts of the printed form that interfere with recognition itself. They can be instructions or field labels within the field itself. This additional printed text can “confuse” the recognizers during their job and negatively affect performance. For handwritten forms, noise can also be in the form of overlapping entries – where information written in one field goes into another field’s space. This also can confuse recognizers during their work. [see attached; also create a photo of a form entry that overlaps into another entry]
Remedies for pre-printed noise include the ability to remove this information based upon a template – some software tries to remove all pre-printed information while other software can also perform field-by-field removal. The danger of this approach is that this “preprocessing” could erroneously remove the field data itself (if it text). For handwritten forms, the answer is usually to create enough space for the person completing the form to write.
Another remedy is to use what is called “drop-out” ink. These are forms printed with a special color that, when combined with the appropriate scanner, can automatically have the scanner remove all pre-printed text. For instance a scanner can detect a certain color of red and not output anything with that same color in the resulting scanned image. The benefit is obvious – there is no noise to confuse the recognizers. It only has to deal with the quality of the actual information.
Optimizing Data Extraction Accuracy
Even though structured forms represent the easiest of the document continuum to tackle, there are still a lot of considerations when taking on a project. Be sure to thoroughly examine all of the form structures to ensure that your data extraction accuracy is maximized. And, of course, in order to be assured that your project will be successful, you need to utilize a sufficient sample size and associated ground truth in order to test adequately.


